Market Research and Recommendation and Visualization Technique for Business Decision Making - Part 1¶
“Aksara, tadi saya forward studi kasus untuk proyek market research dari Kroma. Sudah masuk?” tanya Senja padaku begitu aku sampai di meja.
“Iya, notifikasinya sudah masuk. Segera kukerjakan ya.”
Aku pun membuka isi email yang dimaksud:
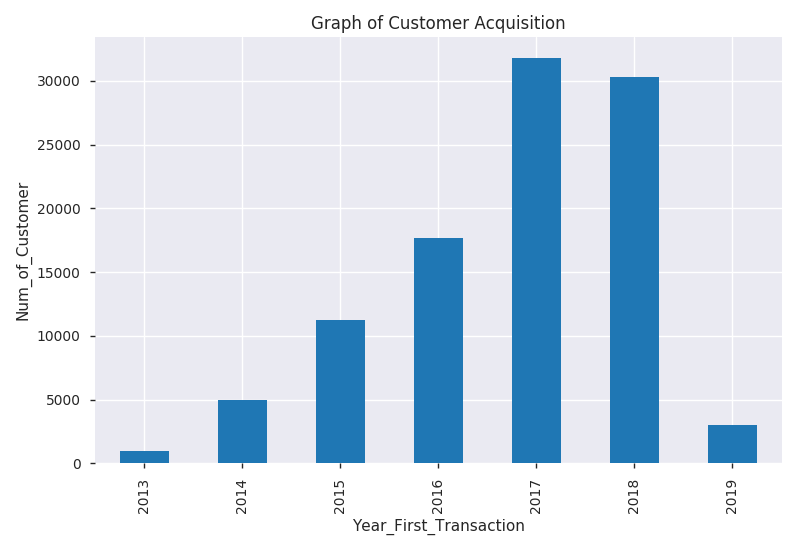
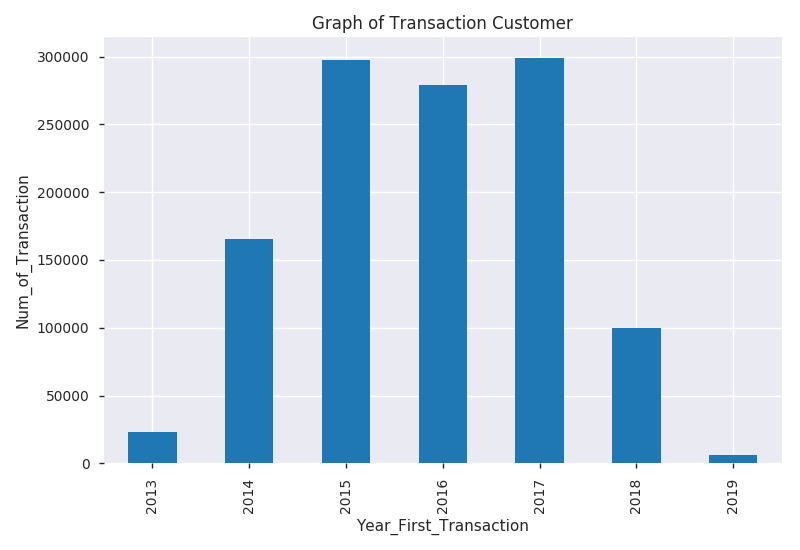
DQLab sport center adalah toko yang menjual berbagai kebutuhan olahraga seperti Jaket, Baju, Tas, dan Sepatu. Toko ini mulai berjualan sejak tahun 2013, sehingga sudah memiliki pelanggan tetap sejak lama, dan tetap berusaha untuk mendapatkan pelanggan baru sampai saat ini.
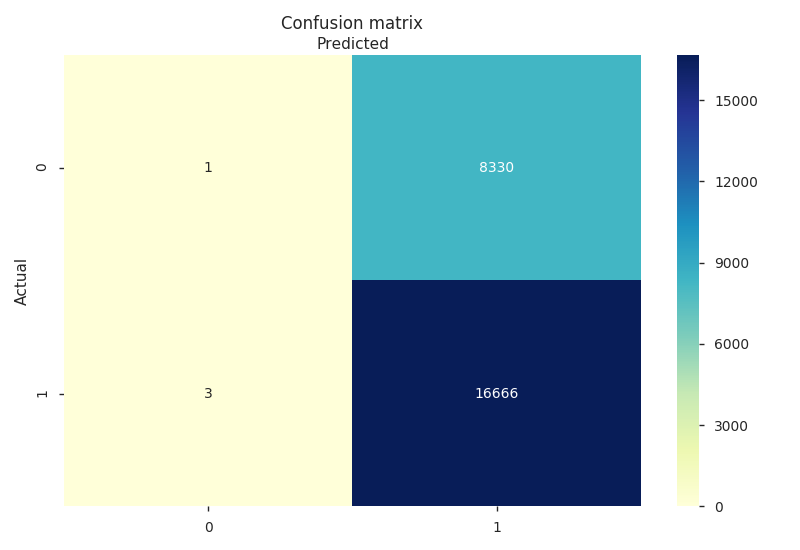
Di awal tahun 2019, manajer toko tersebut merekrut junior DA untuk membantu memecahkan masalah yang ada di tokonya, yaitu menurunnya pelanggan yang membeli kembali ke tokonya. Junior DA tersebut pun diberi kepercayaan mengolah data transaksi toko tersebut. Manajer toko mendefinisikan bahwa customer termasuk sudah bukan disebut pelanggan lagi (churn) ketika dia sudah tidak bertransaksi ke tokonya lagi sampai dengan 6 bulan terakhir dari update data terakhir yang tersedia.
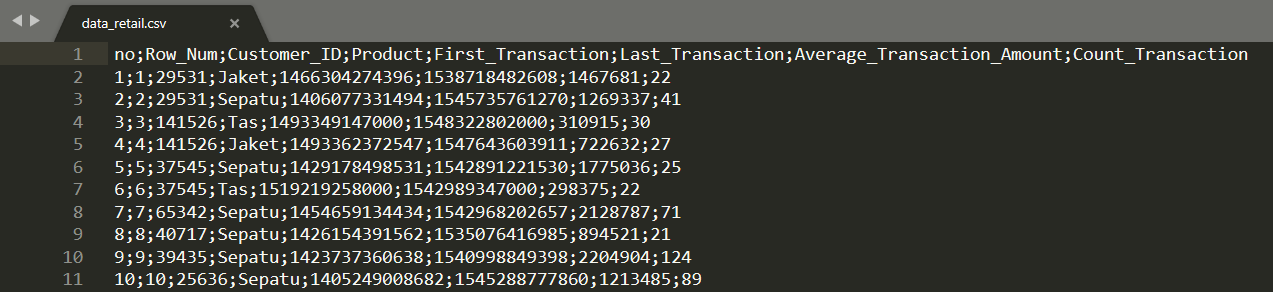
Manajer toko pun memberikan data transaksi dari tahun 2013 sampai dengan 2019 dalam bentuk csv (comma separated value) dengan data_retail.csv dengan jumlah baris 100.000 baris data.
Berikut tampilan datanya:

Field yang ada pada data tersebut antara lain:
- No
- Row_Num
- Customer_ID
- Product
- First_Transaction
- Last_Transaction
- Average_Transaction_Amount
- Count_Transaction